
Welcome all, below you can find a quick guide to allow you to take CSV with a list of up to 50,000 keywords and cluster them and add the keyword intent as well.
Gimme! Gimme! Gimme! the script now – Take a copy or use the script now!
On this page
Thank you to these geniuses
I have Frankensteined a couple of scripts together to build exactly what I want to shout out to these geniuses for both of their scripts. I have very much merged them and made some changes to suit my use! You guys rock!
Semantic Clustering Tool
Website: https://www.searchsolved.co.uk
Twitter: https://twitter.com/LeeFootSEO
Keyword Intents
Website Article https://importsem.com/use-python-to-label-query-intent-entities-and-keyword-count/
Twitter https://twitter.com/GregBernhardt4
Jump to my Google Colab Script: Keyword Clustering Intent
What is keyword topic clustering?*
Keyword topic clustering is a technique used in search engine optimization (SEO) to group related keywords based on their semantic meaning. This process helps organize and optimize website content, allowing search engines better to understand the topic and intent behind the keywords.
One popular tool used for semantic keyword clustering is Python, a programming language known for its versatility and ease of use. By utilizing Python libraries and algorithms, SEO professionals can analyze large sets of keywords and identify patterns or similarities between them. This allows them to create clusters of keywords that share common themes or intent.
What is keyword intent and how can we categorise them?*
Understanding keyword intent is crucial. Keyword intent refers to the underlying motivation or purpose behind a user’s search query. By categorizing keywords based on their intent, we can optimize their content to better align with what users are looking for. This not only improves search engine rankings but also enhances the overall user experience.
Keyword intent categorization involves analyzing search queries and classifying them into different intent categories. There are generally four main types of keyword intent: informational, navigational, transactional, and commercial investigation.
Informational Intent Keywords:
Users utilize these in search of knowledge or solutions to particular queries. They generally contain terms like who, what, when, where, why, how, can, will etc. They could also be entities such as movie names or song names. Anytime a user wants more information and isn’t going to action something online or in-store it is an informational keyword.
- What is a German Shepherd?
- My Chemical Romance
- Is Deception Bay a safe suburb?
Navigational Intent Keywords:
These keywords signal that users aim to find a specific website or brand. They already have a destination in mind and use search engines to navigate directly there. This could be to land on a specific product or brand in e-commerce as well.
Examples:
- Bunnings warehouse
- Kong dog toys
- Semrush login
Transactional Intent Keywords:
These keywords indicate users’ readiness to buy or perform a particular action. They denote a high intent to engage in a commercial activity, such as making a purchase.
Examples:
- buy dog food
- cheap blue dress
- books for sale
Commercial Investigation Keywords:
Employed by users who are in the process of comparing their purchasing options. These potential customers are gathering information and evaluating alternatives before finalizing their buying decisions.
- Compare dog toys
- ahref vs semrush
- best tech SEO tool (Obviously Screaming Frog duh)
My issue with the above keyword intent categorisation?
Whenever a tool automatically builds this into its keyword data, I constantly find it not quite right. So, this is part of the reason I built it into the below python script.
I also seem to find that commercial and transactional can have a massive overlap. Across most the verticles I work across be that hobby pet store or financial websites I find myself targeting both commercial and transaction together.
Finally, I don’t love ‘navigational’ as a grouping for things in the pet industry either. Tools end up grouping your own brand names, product brand names and specific products into navigational together.
So because of all these nuances and maybe cause, I’m a control freak, I prefer to set them myself.
How to use Google Colab Python Script
I am writing this for complete beginners as I know many SEOs have never coded before or used Google Colab.
Google Colab is a free coding notebook, so you can go ahead and open up my script: Keyword Clustering Intent and take a copy. Just like you would with any other Google Drive Doc, Sheet, Slide etc.
Then working from the top you’ll click play next to each set of code and let it run.
CSV Structure or download my example:
Please ensure your document is a csv not Excel file and has 2 columns, your keywords in the first, and search volumes in the second.
| Keyword | Search Volume |
| cat | 201000 |
| dog | 165000 |
Decide on your Keyword Intent Categories
These are mine, you can alter them however you’d like. It’s going to look for these words when deciding on intent.
# Define your intent categories informative = ['what', 'who', 'when', 'where', 'which', 'why', 'how', 'can '] transactional = ['buy', 'order', 'purchase', 'cheap', 'price', 'discount', 'shop', 'sale', 'offer', 'snuffle mat', 'pet crate', 'food', 'toy', 'feeder', 'collar', 'bed', 'hardness', 'ball', 'carrier', 'litter', 'bowl', 'best', 'top', 'review', 'comparison', 'compare', 'vs', 'versus', 'guide', 'worm treatment'] branded = ['royal canin', 'revolution', 'science diet', 'bravecto', 'balance life', 'black hawk', 'adaptil']
Step 1: Run Pip
If you haven’t used colab before, there are little play buttons in the top left corner of the code. Click play. This will install the needed libraries for the code.
You’ll get a green tick when it’s done.
For this script we are using 4 libraries:
Sentence_transformers
Sentence Transformers is a python framework from sbert.net that allows us to compute sentence and text embeddings. It can then compare similarities allowing us to use it to cluster keywords.
Pandas
If you’ve ever used python before you’ve probably heard of Pandas which allows us to analyse and manipulate data. It’s an amazing tool and looks after our data frames.
Chardet
Chardet allows us to detect a various range of Character Encodes so it helps with working with CSVs.
Detect_demlimiter
This helps us detect the delimiter of the csv. So whether is a comma or pipe or semicolon etc.
[',', ';', ':', '|', '\t']Step 2: Run python imports
We then need to import the libraries we want to use. Same thing, click play.
import sys import time import sys import pandas as pd import chardet import codecs from detect_delimiter import detect from google.colab import files from sentence_transformers import SentenceTransformer, util
Step 3: Upload CSV Keyword & Volume File
- Script expects keywords to be in the first column
- Script expects search volumes to be in the second column
- Expects a csv file
- Recommend No More Than 50K Rows
Click play and a upload option will appear allowing you to upload a file.
# upload the keyword export upload = files.upload() input_file = list(upload.keys())[0] # get the name of the uploaded file
Step 4: Run Cluster Accuracy, Size & Choose Sentence Transformer
You can change these figures if you wish.
cluster_accuracy:
0-100 (100 = very tight clusters, but higher percentage of no_cluster groups)
min_cluster_size:
set the minimum size of cluster groups. (Lower number = tighter groups)
Sentence Transformer
Defaulted to the faster one. The best quality option runs better on a premium colab subscription.
To change this uncomment “#” the first one, comment out the second one.
Pre-Trained Models: https://www.sbert.net/docs/pretrained_models.html
cluster_accuracy = 85 # 0-100 (100 = very tight clusters, but higher percentage of no_cluster groups) min_cluster_size = 2 # set the minimum size of cluster groups. (Lower number = tighter groups) #transformer = 'all-mpnet-base-v2' # provides the best quality transformer = 'all-MiniLM-L6-v2' # 5 times faster and still offers good quality
Step 6: Run CSV Checker
This confirms which character enconding your csv is and makes changes if needed.
# automatically detect the character encoding type
acceptable_confidence = .8
contents = upload[input_file]
codec_enc_mapping = {
codecs.BOM_UTF8: 'utf-8-sig',
codecs.BOM_UTF16: 'utf-16',
codecs.BOM_UTF16_BE: 'utf-16-be',
codecs.BOM_UTF16_LE: 'utf-16-le',
codecs.BOM_UTF32: 'utf-32',
codecs.BOM_UTF32_BE: 'utf-32-be',
codecs.BOM_UTF32_LE: 'utf-32-le',
}
encoding_type = 'utf-8' # Default assumption
is_unicode = False
for bom, enc in codec_enc_mapping.items():
if contents.startswith(bom):
encoding_type = enc
is_unicode = True
break
if not is_unicode:
# Didn't find BOM, so let's try to detect the encoding
guess = chardet.detect(contents)
if guess['confidence'] >= acceptable_confidence:
encoding_type = guess['encoding']
print("Character Encoding Type Detected", encoding_type)
Step 7: Run to create DataFrames
# automatically detect the delimiter
with open(input_file,encoding=encoding_type) as myfile:
firstline = myfile.readline()
myfile.close()
delimiter_type = detect(firstline)
# create a dataframe using the detected delimiter and encoding type
df = pd.read_csv((input_file), on_bad_lines='skip', encoding=encoding_type, delimiter=delimiter_type)
count_rows = len(df)
if count_rows > 50_000:
print("WARNING: You May Experience Crashes When Processing Over 50,000 Keywords at Once. Please consider smaller batches!")
print("Uploaded Keyword CSV File Successfully!")
dfkeyword = df
# Get the name of the first column
first_column_name = df.columns[0]
second_column_name = df.columns[1]
# If the first column is not named 'Keyword', rename it
if first_column_name != "Keyword":
df.rename(columns={first_column_name: "Keyword", second_column_name: "Search Volume"}, inplace=True)
# Continue with your data processing
cluster_name_list = []
corpus_sentences_list = []
df_all = []
corpus_set = set(df['Keyword'])
corpus_set_all = corpus_set
cluster = True
Step 8: Run Clustering Keywords – This can take a while!
# keep looping through until no more clusters are created
cluster_accuracy = cluster_accuracy / 100
model = SentenceTransformer(transformer)
while cluster:
corpus_sentences = list(corpus_set)
check_len = len(corpus_sentences)
corpus_embeddings = model.encode(corpus_sentences, batch_size=256, show_progress_bar=True, convert_to_tensor=True)
clusters = util.community_detection(corpus_embeddings, min_community_size=min_cluster_size, threshold=cluster_accuracy)
for keyword, cluster in enumerate(clusters):
print("\nCluster {}, #{} Elements ".format(keyword + 1, len(cluster)))
for sentence_id in cluster[0:]:
print("\t", corpus_sentences[sentence_id])
corpus_sentences_list.append(corpus_sentences[sentence_id])
cluster_name_list.append("Cluster {}, #{} Elements ".format(keyword + 1, len(cluster)))
df_new = pd.DataFrame(None)
df_new['Cluster Name'] = cluster_name_list
df_new["Keyword"] = corpus_sentences_list
df_all.append(df_new)
have = set(df_new["Keyword"])
corpus_set = corpus_set_all - have
remaining = len(corpus_set)
print("Total Unclustered Keywords: ", remaining)
if check_len == remaining:
break
# make a new dataframe from the list of dataframe and merge back into the orginal df
df_new = pd.concat(df_all)
df = df.merge(df_new.drop_duplicates('Keyword'), how='left', on="Keyword")
df
# rename the clusters to the shortest keyword in the cluster
df = df.sort_values(by="Search Volume", ascending=False)
df['Cluster Name'] = df.groupby('Cluster Name')['Keyword'].transform('first')
df.sort_values(['Cluster Name', "Search Volume"], ascending=[True, False], inplace=True)
df['Cluster Name'] = df['Cluster Name'].fillna("zzz_no_cluster")
# move the cluster and keyword columns to the front
col = df.pop("Keyword")
df.insert(0, col.name, col)
col = df.pop('Cluster Name')
df.insert(0, col.name, col)
df.sort_values(["Cluster Name", "Keyword"], ascending=[True, True], inplace=True)
df
uncluster_percent = (remaining / count_rows) * 100
clustered_percent = 100 - uncluster_percent
print(clustered_percent,"% of rows clustered successfully!")
Step 9: Apply Intents
In this part of the code you will need to make changes to suit your intents. And you can choose whatever groupings you want as well.
Update below intents, feel free to add more if you wish. These are Greg’s defaults:
# Define your intent categories transactional = ['buy','order','purchase','cheap','price','discount','shop','sale','offer'] commercial = ['best','top','review','comparison','compare','vs','versus','guide','ultimate'] informational = ['what','who','when','where','which','why','how'] custom = ['brand variation 1','brand variation 2','brand variation 3']
The next step is to update below if you changed the defaults:
# Update 'Intent' based on filters directly in 'df'
df.loc[df['Keyword'].str.contains('|'.join(transactional), case=False, na=False), 'Intent'] = df['Intent'] + ' Transactional'
df.loc[df['Keyword'].str.contains('|'.join(commercial), case=False, na=False), 'Intent'] = df['Intent'] + ' Commercial'
df.loc[df['Keyword'].str.contains('|'.join(informational), case=False, na=False), 'Intent'] = df['Intent'] +' Informational'
df.loc[df['Keyword'].str.contains('|'.join(custom), case=False, na=False), 'Intent'] = df['Intent'] +' Custom'
Final Step!
Run the last bit of code and it’ll output your clustered CSV!
df_intents.to_csv('clustered.csv', index=False)
files.download("clustered.csv")
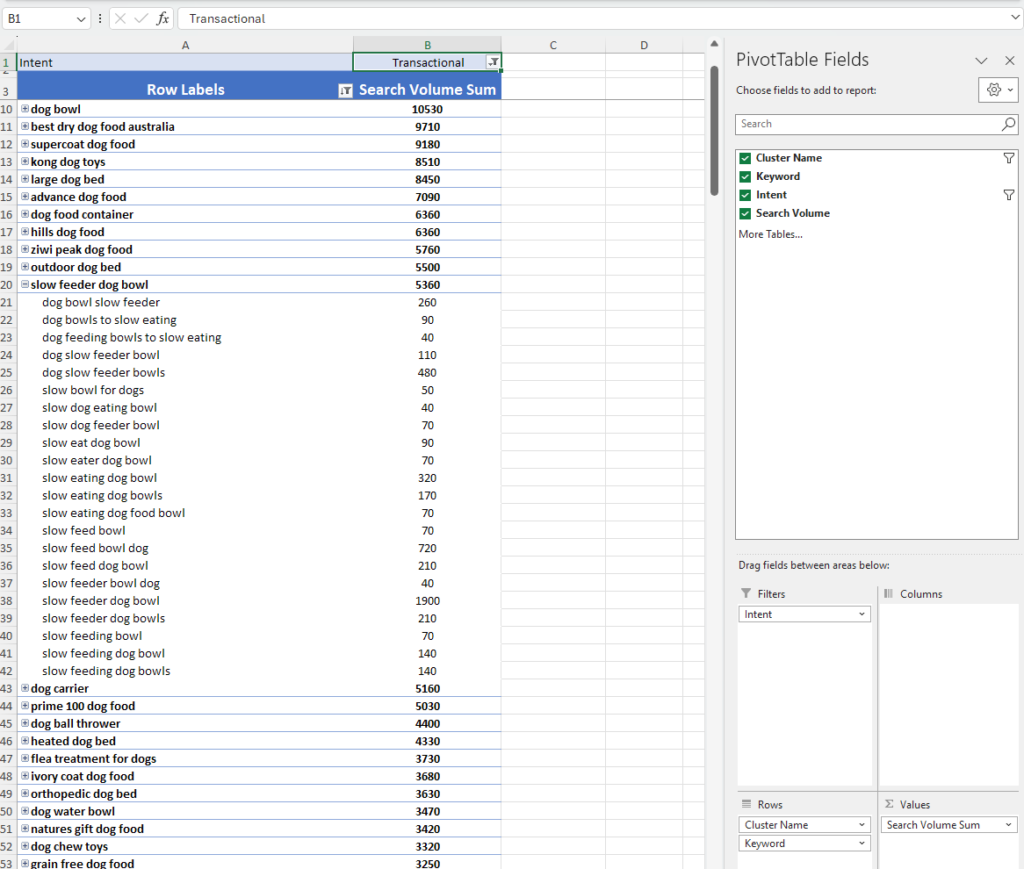
You can then put these into a pivot table to allow you to filter by intent and find your next topic to target!
Here is an example of mine:
If you have any questions feel free to reach out through email or twitter or comment below!

Leave a Reply