
Often as SEO’s we need to review content and data points on different URLs. Screaming Frog is an amazing tool for this but when we are working with a list of less than 1,000 and only need a couple of data points I find it way easier to use Google Sheets in built Scraping.
Gimme! Gimme! Gimme! the Google sheet now – Take a copy or check out the formulas now!
On this page
What’s XPath?*
XPath (XML Path Language) is a query language used for selecting nodes from an XML (or HTML) document. It allows you to navigate through the elements and attributes of an XML document, enabling you to pinpoint specific parts of the document’s structure.
XPath expressions can be used in various programming languages and tools for tasks such as data extraction, validation, transformation, and traversal of XML documents. It provides a syntax for selecting nodes based on their properties, relationships, and positions within the document hierarchy.
Basically, XPath lets you target a specific HTML element such a h1 or a meta title etc.
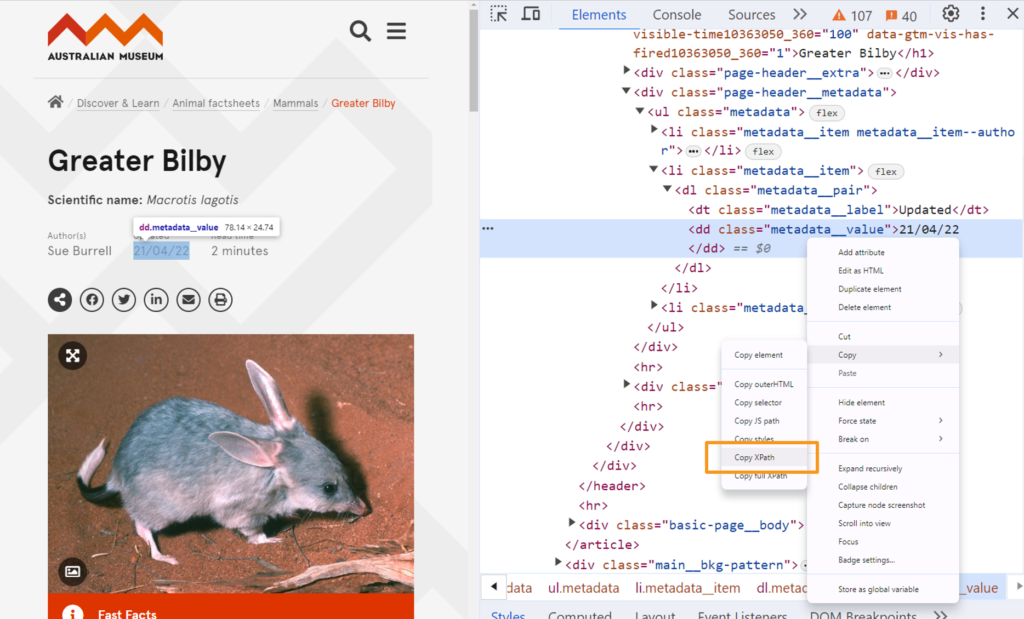
You can get the XPath in dev tools by copying the element you want to capture.
ImportXML for SEO Basics
The examples below will all work on the following cute page from the Australian Museum as an example in cell A2:
https://australian.museum/learn/animals/mammals/greater-bilby/
They should work on your website too assuming you have the element on the page. If you have more than one of these elements on a page see my troubleshooting at the bottom.
H1
<h1>Greater Bilby</h1>
XPath = //h1
Xpath to HTML Break down:
- //h1 looks for <h1>
| Google Sheet Formula | Output |
|---|---|
| =IMPORTXML(A2,”//h1″) | Greater Bilby |
Meta Title / Page Title
<title>Greater Bilby - The Australian Museum</title>
XPath = //title
Xpath to HTML Breakdown:
- //title looks for <title>
| Google Sheet Formula | Output |
|---|---|
| =IMPORTXML(A2,”//title”) | Greater Bilby – The Australian Museum |
Meta Description
<meta name="description" content="The Greater Bilby, sometimes depicted as Australia's Easter Bunny, belongs to a group of ground-dwelling marsupials known as bandicoots.">
XPath = //meta[@name=’description’]/@content
Xpath to HTML Break down:
- //meta looks for <meta
- [@name=’description’] looks for name=”description”
- /@content looks for content=”The Greater Bilby…..
Formula:
| Google Sheet Formula | Output |
|---|---|
| =IMPORTXML(A2,”//meta[@name=’description’]/@content”) | The Greater Bilby, sometimes depicted as Australia’s Easter Bunny, belongs to a group of ground-dwelling marsupials known as bandicoots. |
Canonical
<link rel="canonical" href="https://australian.museum/learn/animals/mammals/greater-bilby/">
XPath = //link[@rel=’canonical’]/@href
Xpath to HTML Break down:
- //link looks for <link
- [@rel=’canonical’] looks for rel=”canonical”
- /@href looks for href=”https://australi…
Formula:
| Google Sheet Formula | Output |
|---|---|
| =IMPORTXML(A2,”//link[@rel=’canonical’]/@href”) | https://australian.museum/learn/animals/mammals/greater-bilby/ |
H2/H3/H3 etc.
<h2>H2 1</h2> <p>Some text</p> <h2>H2 3</h2> <p>Some text</p> <h2>H2 3</h2> <p>Some text</p>
XPath = //h2
Xpath to HTML Break down:
- //h2 looks for all <h2>
Formula:
When there are multiple values you’ll need to use transpose to make sure it doesn’t overwrite content in the cell below.
| Google Sheet Formula | Output Col 1 | Output Col 2 | Output Col 3 |
|---|---|---|---|
| =transpose(IMPORTXML(A2,”//h2)) | H2 1 | H2 2 | H2 3 |
Custom ImportXml
Sometimes we want to grab say authors or dates of articles. So we need to use a bit more complex XML. The two below are quite complicated but all you really need to know is you can copy XPath and use it.
Date & Author Example
https://australian.museum/learn/animals/mammals/greater-bilby/
<main id="main"> .. <article> <div class="page-header__metadata"> <ul class="metadata"> <li class="metadata__item metadata__item--author"> <dl class="metadata__pair"> <dt class="metadata__label">Author(s)</dt> <dd class="metadata__value">Sue Burrell</dd> </dl> </li> <li class="metadata__item"> <dl class="metadata__pair"> <dt class="metadata__label">Updated</dt> <dd class="metadata__value">21/04/22</dd> </dl> </li> <li class="metadata__item"> <dl class="metadata__pair"> <dt class="metadata__label">Read time</dt> <dd class="metadata__value">2 minutes</dd> </dl> </li> </ul> </div> .. </article> </main>
Date
Date XPath = //*[@id=’main’]/article/header/div/div/div/div/ul/li[2]/dl/dd”
Formula:
| Google Sheet Formula | Output |
|---|---|
| =importxml(A2,”//*[@id=’main’]/article/header/div/div/div/div/ul/li[2]/dl/dd”) | 28/04/22 |
Author
Author XPath = //*[@id=’main’]/article/header/div/div/div/div/ul/li[contains(@class, ‘metadata__item metadata__item–author’)]/dl/dd
Formula:
| Google Sheet Formula | Output |
|---|---|
| =importxml(A2,”//*[@id=’main’]/article/header/div/div/div/div/ul/li[contains(@class, ‘metadata__item metadata__item–author’)]/dl/dd”) | Sue Burrell |
Troubleshooting
I have more than one value for the element and it is overwriting the one below.
You can use the =transpose(importXML(A2, “XPATH”) to cater for this. Transpose will instead add the values in the next column instead of row.
My value isn’t working and I copied straight from dev tools?
Watch out for the different quotation marks.
Xpath in Chrome Dev Tools uses ” ” around attributes
Google Sheets uses ‘ ‘ around attributes
If you have any questions feel free to reach out through email or twitter or comment below!
Leave a Reply